importos# First, I generate list of strings with relevant filenames in 4 folders
train_neg_image_filenames=['./data1/aclImdb/train/neg/'+iforiin(os.listdir('./data1/aclImdb/train/neg/'))]train_pos_image_filenames=['./data1/aclImdb/train/pos/'+iforiin(os.listdir('./data1/aclImdb/train/pos/'))]test_neg_image_filenames=['./data1/aclImdb/test/neg/'+iforiin(os.listdir('./data1/aclImdb/test/neg/'))]test_pos_image_filenames=['./data1/aclImdb/test/pos/'+iforiin(os.listdir('./data1/aclImdb/test/pos/'))]# I create variable 'data' including all reviews, 1 string per 1 review.
# I access folder using above filenames and write content of files to list 'data'
data=list()a=list()foriintrain_neg_image_filenames:withopen(i,"r")asmyfile:a=(myfile.read().replace('\n',''))data.extend([a])foriintrain_pos_image_filenames:withopen(i,"r")asmyfile:a=(myfile.read().replace('\n',''))data.extend([a])foriintest_neg_image_filenames:withopen(i,"r")asmyfile:a=(myfile.read().replace('\n',''))data.extend([a])foriintest_pos_image_filenames:withopen(i,"r")asmyfile:a=(myfile.read().replace('\n',''))data.extend([a])# I assigned the labels to respective reviews stored in list
# I can do this, because reviews in list are stored in order
# 0 means that the review is negative, 1 that the review is positive
labels=list()foriinrange(len(train_neg_image_filenames)):labels.extend([0])foriinrange(len(train_pos_image_filenames)):labels.extend([1])foriinrange(len(test_neg_image_filenames)):labels.extend([0])foriinrange(len(test_pos_image_filenames)):labels.extend([1])# I first zip data together (so that label and respective file are together), shuffle them, and separate them again
importrandomtrain=list(zip(data,labels))random.shuffle(train)data,labels=zip(*train)
fromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesimportnumpyasnpfromkeras.preprocessing.textimporttext_to_word_sequencefromkeras.utilsimportto_categorical# I iterate through element of the list 'data' keeping 100 words of each review in list 'data_100'
# This accelerates the whole process
# We need to assume that first 100 workds can give accurate indication about the overall meaning of the review
fromkeras.utilsimportto_categoricaldata_100=list()foriinrange(len(data)):a=text_to_word_sequence(data[i])a=a[:100]a=' '.join(a)data_100.append(a)# I fit tokenizer to the reduced reviews, keep 5000 most frequent words, transform all data to lower case
# By use texts_to_sequences I transform each text to a sequence of integers
# pad_sequences transforms list of integers to required 2D Numpy array
tok=Tokenizer(num_words=5001,lower=True,split=" ")tok.fit_on_texts(data_100)sequences=tok.texts_to_sequences(data_100)word_index=tok.word_indexdata_100=pad_sequences(sequences)# I declare labels to be categorical variables, which creates set of 2 dimensional np arrays with binary indicator
labels=to_categorical(np.asarray(labels))print('Shape of data tensor:',data_100.shape)# displaying the dimension of the data
print('Shape of label tensor:',labels.shape)# displaying the dimension of labels
# I split training and testing set
# As requested, I restricted training set to 1000 reviews, but this may not be enought for ML model
train_data=data_100[:1000]test_data=data_100[1001:]# Splitting training labels accordingly
train_labels=labels[:1000]test_labels=labels[1001:]
importpandasaspdimportsysimportcsv# Reading embedding layer, which will be directly passed to a network
# This safes computational time
# First, we read a whole file and later iterate through it reading word indexes
embeddings_index={}# create a dictionary
file=open(os.path.join('./data1/glove.6B/','glove.6B.100d.txt'))# open a file
forlineinfile:# iterate through file reading words and creating embedding index
values=line.split()word=values[0]coefs=np.asarray(values[1:],dtype='float32')embeddings_index[word]=coefsfile.close()# we stop reading the file
# Use tokeniser trained on our data
word_index=tok.word_index# assign all unique words to word_index variable
# Last, we create an embedding matrix, including 100 dimensions
embedding_matrix=np.zeros((len(word_index)+1,100))# define embedding matrix shape
forword,iinword_index.items():# fill the embedding matrix
embedding_vector=embeddings_index.get(word)ifembedding_vectorisnotNone:embedding_matrix[i]=embedding_vector
fromkeras.modelsimportSequentialfromkeras.layersimportEmbedding,Flatten,Dense# I import embedding layer from keras library
fromkeras.layersimportEmbedding# Declaring the embedding layes, first I declare its size, the number of dimensions (100), I pass the weights
# which has been already trained, input length is 100, because I have limited the size of each review to 100 words,
# and setting parameter to trainable = False, because otherwise the model would start training the layer
embedding_layer=Embedding(len(word_index)+1,100,weights=[embedding_matrix],input_length=100,trainable=False)# I set up a simple NN model, with declared trained embedding layer. Next I flatten the layer and pass the input to
# the dense layer with sigmoid activation function, because there are only two possibilities of classification
# (either positive or negative review). I use ''rmsprop'' as optimizer
model=Sequential()model.add(embedding_layer)model.add(Flatten())model.add(Dense(2,activation='sigmoid'))model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])print(model.summary())#Printing the model summary
# fitting the model, with validation split 0.1 and 50 epochs
history=model.fit(train_data,train_labels,epochs=50,validation_split=0.1)
importmatplotlib.pyplotasplt# Plotting the validation accuracy and validaiton loss.
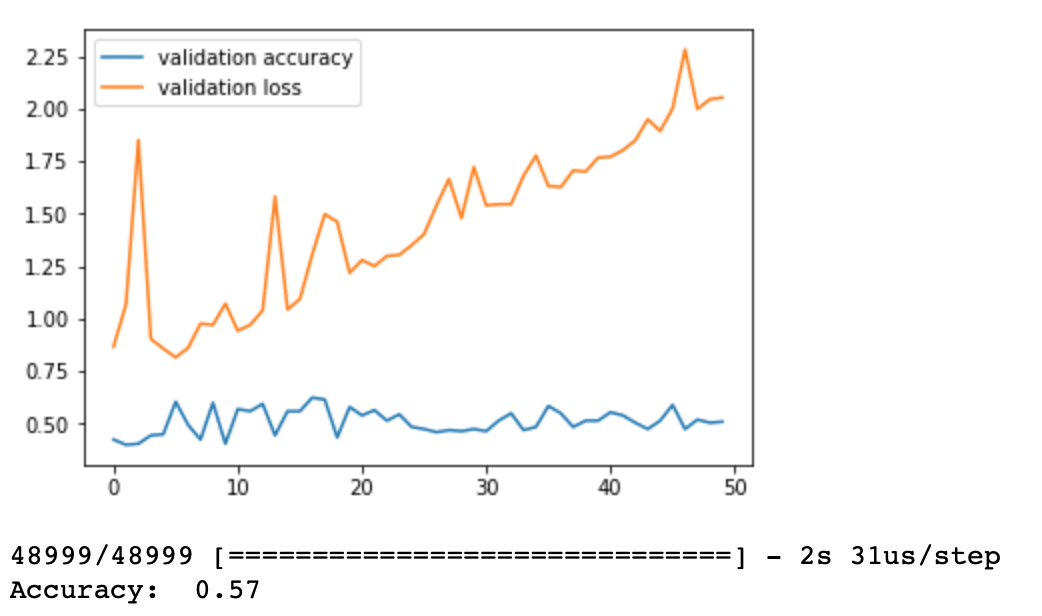
plt.plot(history.history['val_acc'],label='validation accuracy')plt.plot(history.history['val_loss'],label='validation loss')plt.legend()plt.show()# evaluate the model
loss,accuracy=model.evaluate(test_data,test_labels)print('Accuracy: ',round(accuracy,2))# We can note that validation loss is increasing, while the validation accuracy remains constant
# This phenomenon is visible, because we work on trained neural network, we dont actually train the model
# thus accuracy is constant all the time
# In general, model performs very poorly, because the accuracy of training data set is 0.57, and this
# is binary classification. So it's just slightly better, than random classification (then accuracy would be 0.5)
fromkeras.layersimportLSTM# Setting up model, by adding the LSTM layer
model=Sequential()model.add(embedding_layer)# Adding embedding layer defined above
model.add(LSTM(100))# Adding LSTM layer with 100 cells
model.add(Dense(2,activation='sigmoid'))# Output later has sigmoid activation because it's binary choice
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])# same specification as above
print(model.summary())# fit the model
history=model.fit(train_data,train_labels,epochs=20,validation_split=0.1)# Printing results of the model
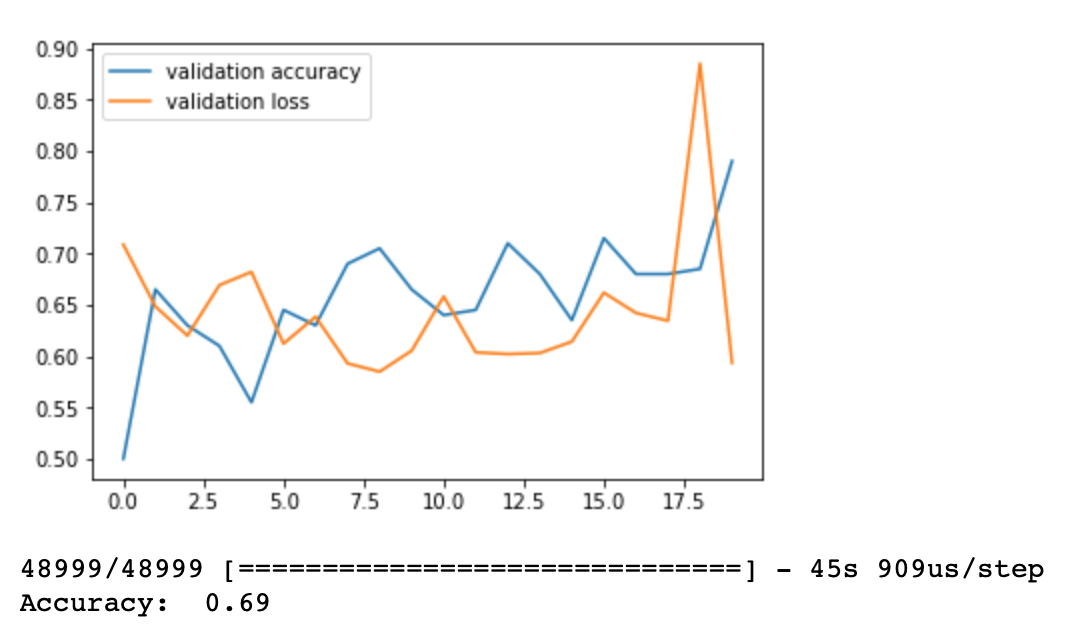
plt.plot(history.history['val_acc'],label='validation accuracy')plt.plot(history.history['val_loss'],label='validation loss')plt.legend()plt.show()# evaluate the model
loss,accuracy=model.evaluate(test_data,test_labels)print('Accuracy: ',round(accuracy,2))# This model is more complex, and performs better (LSTM layer considers sequences of words)
# We may note, that during training both the accuracy and loss are rather constant
# Our model improves just a bit, as we progress
# However there is possible overfitting because training accuracy is very high,
# while validation accuracy remains constant. It means that the model learns our data.
# Probably, I could experiment and increase number of epoch to increase perormance, but this could lead to even more overfitting
# The accuracy based on training data set is 0.69, which is much higher than in model without LSTM layer (by 0.12)
# Thus, we may conclude that adding the LSTM layer is benefitial to the model, as LSTM considers the sequences of words